
Как справить зависимости от настроек браузера в CSS-файлах
При написании CSS-кода, нужно учитывать, что отображение может отличаться в разных браузерах. Это связано с настройками шрифтов, размеров окон и других параметров, которые могут быть индивидуальными для каждого пользователя.
Для того чтобы справиться с этой проблемой, стоит использовать относительные значения в CSS-коде. Например, вместо задания конкретного размера блока, лучше задать отношение ширины блока к ширине родительского элемента. Такой подход позволит более гибко адаптироваться к разным настройкам браузеров.
Также стоит обратить внимание на выбранную цветовую гамму. Некоторые цвета могут отображаться по-разному на разных устройствах и в разных браузерах
Для того чтобы быть уверенными в правильности отображения, можно использовать инструменты для проверки доступности цветовой гаммы.
- Использование относительных значений в CSS-коде
- Выбор правильной цветовой гаммы
- Использование инструментов для проверки доступности цветовой гаммы
Правильное использование мета-тегов
Мета-теги в HTML важны для того, чтобы помочь поисковым системам правильно проиндексировать ваш сайт. Они содержат информацию о том, что можно найти на странице, ключевых словах, описании, авторах и др.
Оптимизация мета-тегов — это важная задача любого SEO-специалиста. Но далеко не каждый знает, как правильно это сделать
Важно знать, какой контент стоит разместить в каждом мета-теге и как правильно заполнить его атрибуты
Для правильной оптимизации мета-тегов важно:
- Заполнить тег title — это самый важный мета-тег для SEO. Он отображается в закладках и результатах поиска.
- Заполнить тег description — здесь записывают краткое описание контента страницы. Он также отображается в результатах поиска.
- Заполнить тег keywords — записываются ключевые слова, связанные с контентом страницы.
- Заполнить теги author и publisher — если вы хотите указать автора и издателя вашего контента.
- Использовать теги robots для индексирования и инструкций по обработке контента.
Пример кода:
| Тег | Описание | Пример |
|---|---|---|
| <title> | Название страницы | <title>Моя страница</title> |
| <meta name=»description» content=»описание страницы»> | Краткое описание контента страницы | <meta name=»description» content=»Лучшие рецепты блинов»> |
| <meta name=»keywords» content=»ключевые слова»> | Ключевые слова, связанные с контентом страницы | <meta name=»keywords» content=»блины, рецепты блинов»> |
| <meta name=»author» content=»автор»> | Автор контента | <meta name=»author» content=»Иван Иванов»> |
| <meta name=»publisher» content=»издатель»> | Издатель контента | <meta name=»publisher» content=»Название издательства»> |
| <meta name=»robots» content=»инструкции»> | Инструкции для поисковых роботов о том, как обрабатывать контент | <meta name=»robots» content=»index, follow»> |
Убираем кракозябры в Windows 7
Основная причина рассматриваемой неполадки – не распознается установленная системой кодировка либо выбрана неправильная таблица перекодировки. Устранить эту проблему можно несколькими методами.
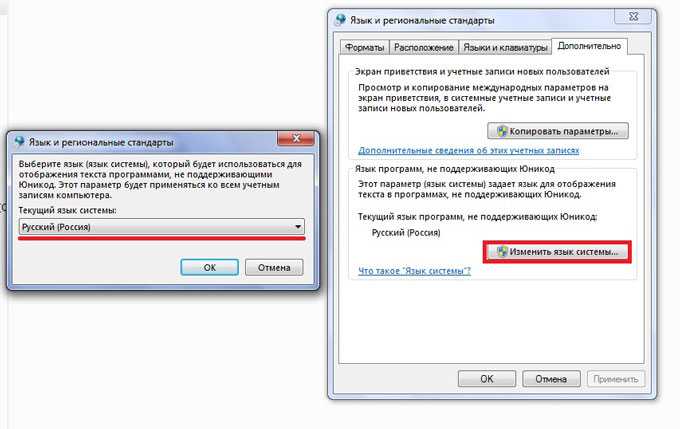
Способ 1: Смена системной локали
В большинстве случаев устранить трудности с распознаванием кодировки можно сменой системной локали – с русской на английскую, затем снова на русскую. Делается это следующим образом:


После рестарта машины проблема с кракозябрами должна быть устранена. Если нет, читайте далее.
Способ 2: Изменение кодировки через системный реестр
Второй метод исправления ошибок с чтением кодировки заключается в ручном выборе требуемых таблиц через системный реестр.
Первый вариант
Альтернативный вариант Первая представленная последовательность замены кодировки неэффективна по времени, но существует способ её ускорить – создать файл REG с заранее прописанными командами.
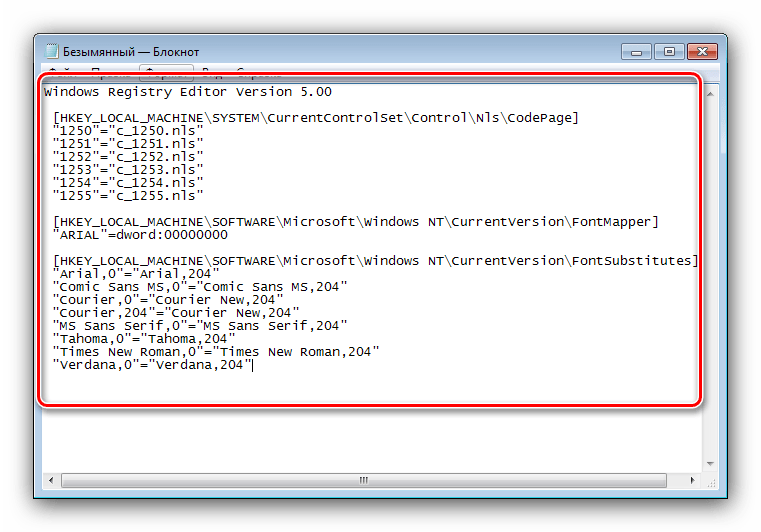
«1250»=»c_1250.nls» «1251»=»c_1251.nls» «1252»=»c_1252.nls» «1253»=»c_1253.nls» «1254»=»c_1254.nls» «1255»=»c_1255.nls»
«ARIAL»=dword:00000000
«Arial,0″=»Arial,204» «Comic Sans MS,0″=»Comic Sans MS,204» «Courier,0″=»Courier New,204» «Courier,204″=»Courier New,204» «MS Sans Serif,0″=»MS Sans Serif,204» «Tahoma,0″=»Tahoma,204» «Times New Roman,0″=»Times New Roman,204» «Verdana,0″=»Verdana,204» HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage
В конце процедуры нажмите «Сохранить».
После этого можно запустить созданный REG-файл двойным щелчком ЛКМ.
Подтвердите, что желаете внести изменения.
В большинстве случаев вышеуказанных действий достаточно для устранения всех проблем с кракозябрами, но стоит иметь в виду, что они могут привести к другим неполадкам, поэтому применять его рекомендуем исключительно в крайнем случае.
Способ 3: Переустановка операционной системы
Описанные выше способы могут не иметь желаемого эффекта – проблема продолжает наблюдаться, несмотря на действия пользователя. В таком случае некорректную ассоциацию таблиц кодировок вручную изменить невозможно, и единственным способом её устранить будет переустановка ОС.
Заключение
Мы рассмотрели методы устранения проблемы с отображением кракозябр вместо нормального текста в Windows 7. Напоследок хотим отметить, что такой сбой чаще всего наблюдается в пиратских «репаках», поэтому ещё раз напоминаем – используйте только лицензионное ПО или его свободные аналоги.
Помимо этой статьи, на сайте еще 12315 инструкций. Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Unicode
GB2312 、 GBK против GB18030 Оба являются наборами символов китайской кодировки. Несмотря на то чтоGB18030 Он также содержит японские и корейские идеограммы, что считается международным набором символов, но, в конце концов, он в основном китайский и не может адаптироваться к глобальным приложениям.
На заре компьютерного развития разные страны ввели свои собственные наборы символов и схемы кодирования, несовместимые друг с другом. Текст, закодированный на китайском языке, не может отображаться в системе, использующей японскую кодировку, что создает препятствия для международного общения.
В это время появился герой.Unicode Alliance Встаньте и скажите, что нужно разработать универсальный набор символов, включающий всех персонажей мира.Unicode . После многих лет разработкиUnicode Он стал наиболее распространенным набором символов в мире и отраслевым стандартом в области информатики.
Unicode Превышено количество уже включенных символов13 Миллион, каждый персонаж должен занимать более2 байт. Так как обычно используемые языки программирования не24 Тип цифры, поэтому обычно используют32 Цифра представляет собой символ. Таким образом, та же самая английская буква вASCII Просто занимай1 Байт вUnicode Нужно занять4 байт! Британцы и американцы плачут, только представьте, размер файла на вашем диске увеличился.4 На что это похоже!
Примеры выполнения заданий
Задачи
Предварительно на листе проекта
ЛогоМиров должно быть создано текстовое окно,
файл должен быть сохранен и в этой же папке
записан текстовый файл пробный.txt.
это подготовка
ct loadtext «пробный top
end
это пробелы
подготовка удаление
end
это удаление
if eot?
select cf copy
if clipboard = char 32
удаление
end
это турецкий_акцент
подготовка акцент
end
это акцент
if eot?
select cf copy
if clipboard = «е
акцент
end
это подстановка :a :b
if eot?
select cf copy
if clipboard = :a
if clipboard = :b
подстановка :a :b
end
это демо_1
подготовка
подстановка «а «е
wait 30 top
подстановка «а «е
end
Процедура демо_1
демонстрирует шифрование текста методом
подстановки. Через три секунды текст
расшифровывается.


это шифровка
if eot?
select cf copy make «n ascii clipboard
if :n > 100
шифровка
end
это расшифровка
if eot?
select cf copy make «n ascii clipboard
if :n > 99
расшифровка
end
это демо_2
подготовка
шифровка wait 30 top расшифровка
end
Процедура демо_2
демонстрирует шифрование текста способом,
указанным в последней задаче. Через три секунды
текст расшифровывается.
Линейные диаграммы
Вывод: если в тексте, закодированном по
CP-1251, попадаются буквы с кодом от 192 до 239, то от
кода необходимо отнять 64. Тогда мы перейдем в CP-866
(это русские буквы от А до п). Для букв с кодами от
240 до 255 (р – я) для перехода из CP-1251 в CP-866 разность
в коде — 16.
Программы перекодировки
это Win-DOS
if eot?
select cf copy make «n ascii clipboard
if and :n > 191 :n < 240
if and :n > 239 :n < 256
Win-DOS
end
это DOS-Win
if eot?
select cf copy make «n ascii clipboard
if and :n > 127 :n < 176
if and :n > 223 :n < 240
DOS-Win
end
это демо_3
подготовка
Win-DOS wait 30 top DOS-Win
end
Процедура демо_3
демонстрирует перевод текста из кодировки CP-1251 в
кодировку CP-866. Затем, через три секунды,
производится обратный перевод.
Методические комментарии к практикуму
Предложенный читателям
“Информатики” практикум — часть базового курса
для 7–9-х классов. Этот вариант курса информатики
построен на нескольких принципах. Во-первых,
различные “линии” курса — программирование,
технология обработки графики, текста, теория
(например, системы счисления) и т.д. — не
разнесены по годам обучения или, скажем, по
полугодиям. А, наоборот, перемежаются и
переплетаются. Во-вторых, новый учебный материал
появляется перед учащимися в тот момент, когда
возникает практическая необходимость. То есть в
контексте некоторого задания или мини-проекта.
Например, разговор о логических операторах
заходит первый раз, когда нужно написать
программу перекодировки. И без нового средства
никак не обойтись. Это не означает, конечно, что
потом не будет обобщения и рассказа и об
Аристотеле, и о Дж. Буле. Другими словами, общий
подход в обучении информатике в данном курсе —
не от общего к частному, а наоборот. Поэтому в
основе лежит цепочка задач, заданий,
мини-проектов и практикумов.
Задания практикума “Кодирование текста”
имеют комплексный характер. Учащиеся и
программируют, и переводят числа из одной
системы счисления в другую, работают с векторным
графическим редактором, подготавливают
иллюстрации для текстового документа (отчета),
форматируют таблицы, используют язык HTML,
работают с браузером и файловым менеджером.
Переходы от одного вида деятельности к другому
не мешают осваивать достаточно сложный раздел
курса. Наоборот, такое разнообразие помогает
поддерживать интерес к работе над заданиями и к
нашему предмету.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:



- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Два способа, как поменять кодировку в Word
Ввиду того, что текстовый редактор “Майкрософт Ворд” является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, “перевести” которые невозможно.
Эти случаи чаще всего связаны лишь с одним – с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой.
Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона.
Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных “неисправностей”, но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В “вордовском” файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
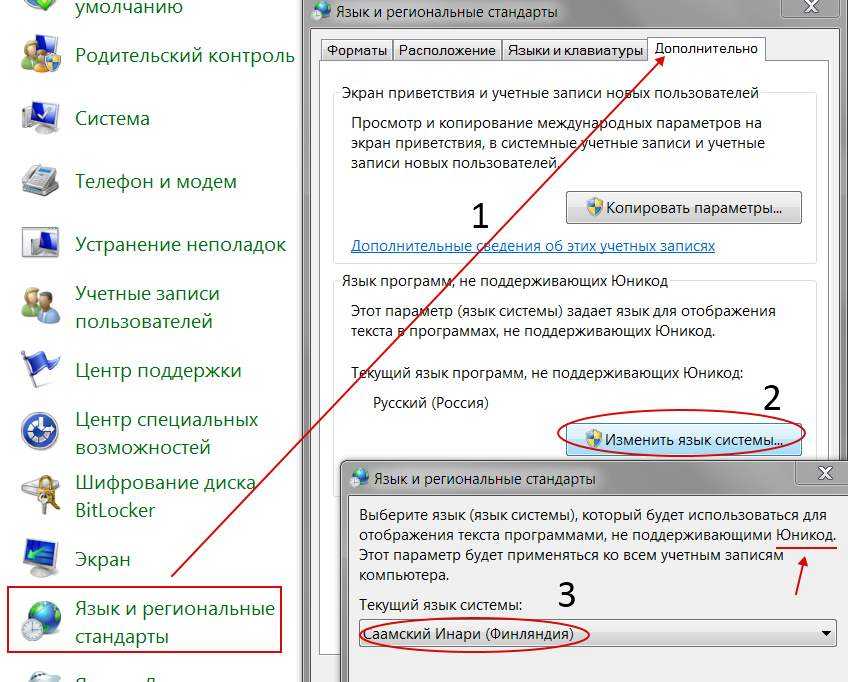
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, – это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку “Файл” (в ранних версиях это кнопка “MS Office”).
- Перейти в категорию “Параметры”.
- Нажать по пункту “Дополнительно”.
- В открывшемся меню пролистать окно до пункта “Общие”.
- Поставить отметку рядом с “Подтверждать преобразование формата файла при открытии”.
- Нажать”ОК”.
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе “Ворд”, будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
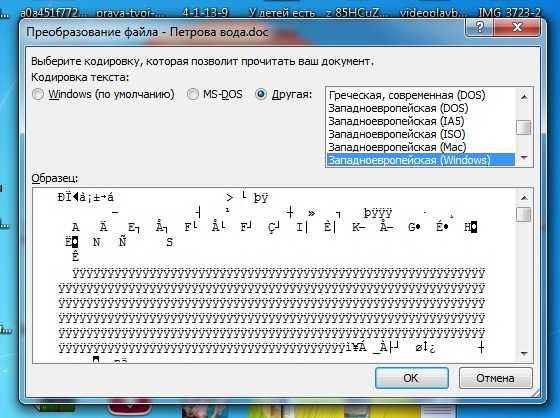
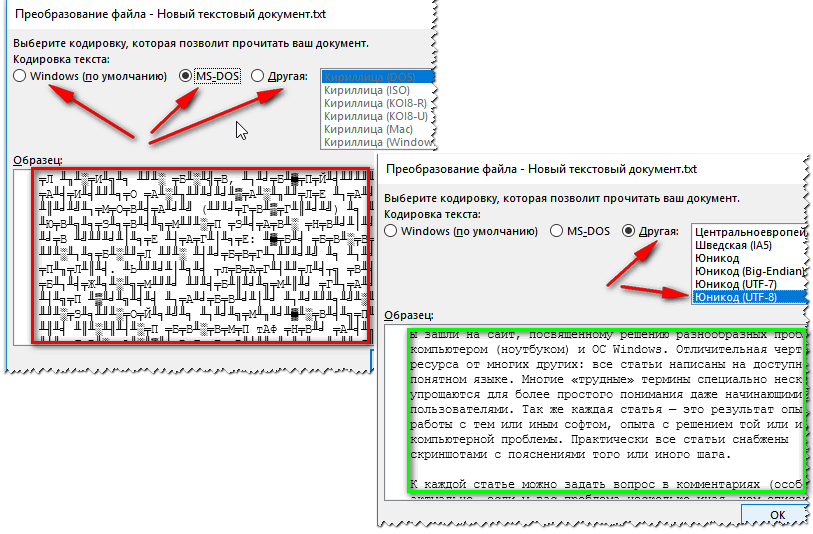
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту “Кодированный текст”, что находится в разделе “Преобразование файла”.
- В появившемся окне установите переключатель на пункт “Другая”.
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите “ОК”.
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне “Образец”. Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
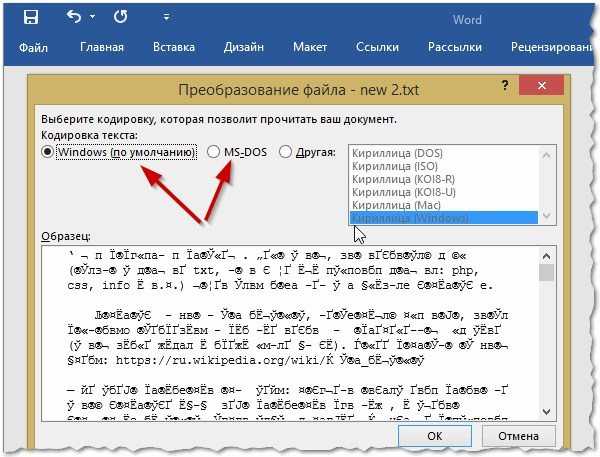
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите “Файл”.
- Выберите “Сохранить как”.
- В выпадающем списке, что находится в разделе “Тип файла”, выберите “Обычный текст”.
- Кликните по “Сохранить”.
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите “ОК”.
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.
Решение проблемы
Сделать это можно несколькими способами:
Способ 1
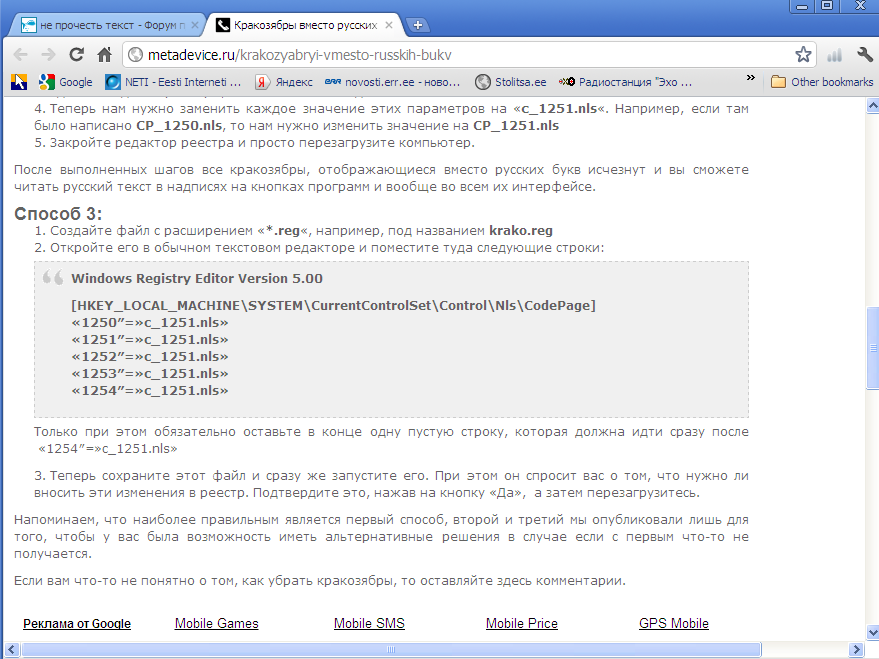
1) открыть «Редактор реестра».
Для этого нужно нажать на клавиатуре кнопку «Windows» (обычно с изображением логотипа Windows, находится в нижнем ряду, слева, между кнопками Ctrl и Alt) и, удерживая ее, нажать кнопку «R» (в русской раскладке «К»). Появится окно запуска программ. В нем нужно написать regedit и нажать кнопку «ОК»;
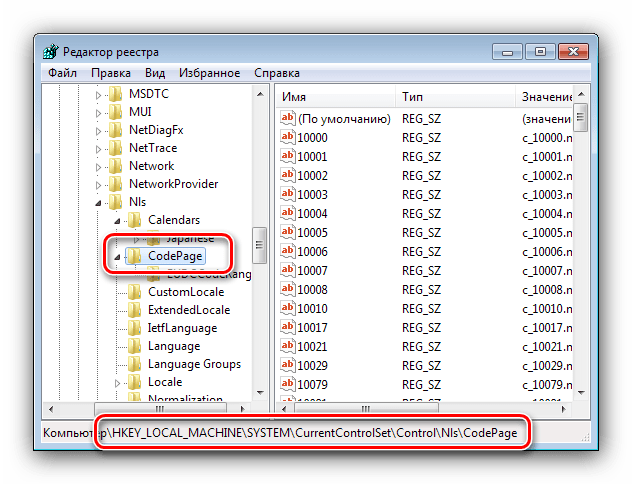
2) последовательно открывая соответствующие папки в левой части «Редактора реестра», зайти в ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage. Это значит, что нужно открыть сначала папку «HKEY_LOCAL_MACHINE», в ней открыть папку «SYSTEM», в ней – «CurrentControlSet» и т.д.;
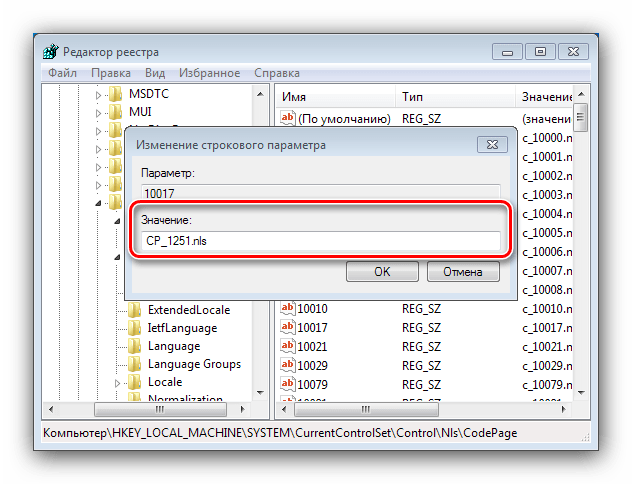
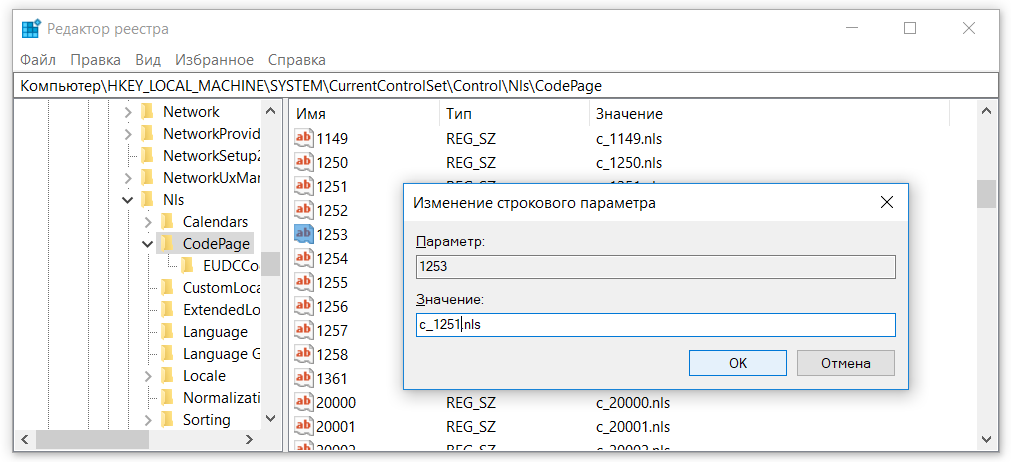
3) когда доберетесь до раздела «CodePage» и выделите его в левой части «Редактора реестра», в его правой части появится довольно большой список параметров. Нужно отыскать среди них параметры «1250», «1252» и «1253».
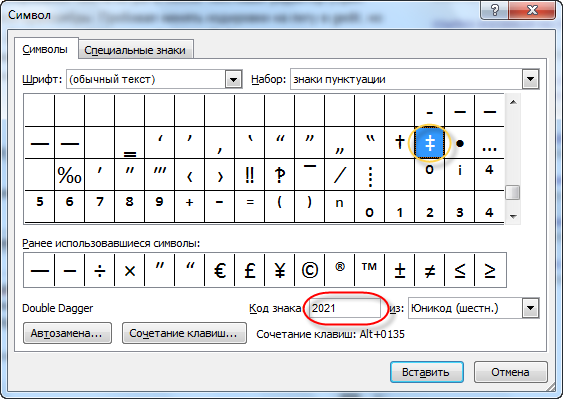
4) дважды щелкнуть мышкой по параметру «1250». Откроется окно «Изменение строкового параметра». В нем содержание поля «Значение» нужно изменить на «c_1251.nls» и нажать кнопку «ОК» (см.рис.).
Затем аналогичным образом изменить на «c_1251.nls» значение параметров «1252» и «1253».

5) закрыть окно редактора реестра и перезагрузить компьютер. После перезагрузки проблема с неправильным отображением шрифтов должна исчезнуть.
Способ 2
Все указанные выше изменения в системный реестр можно внести немного проще, используя соответствующий REG-файл.
Открывать REG-файлы необходимо от имени администратора компьютера.
Подробнее об этом читайте здесь.
Чтобы получить архив с REG-файлом, осуществляющим описанные выше действия, нажмите сюда.
Иероглифы вместо русских букв, вместо текста квадратики, что делать?
Автор Вероника и Влад Дата Ноя 2, 2016
- Текстовые документы
- Notepad +++
- Bred 3
- Word
- Иероглифы в браузере
Текстовые документы
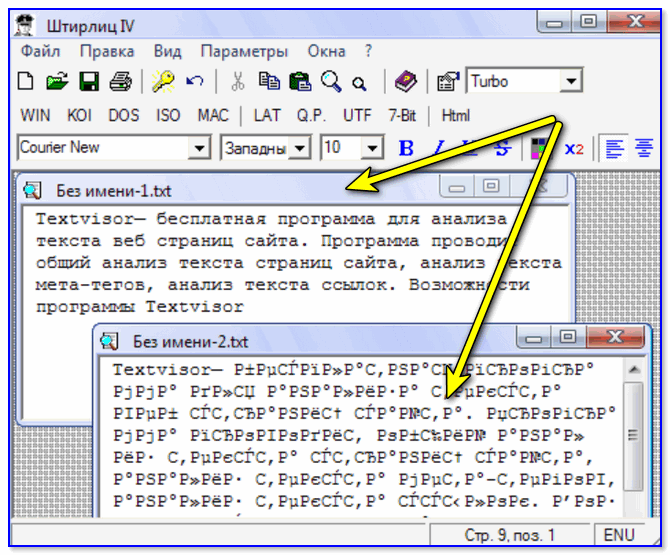
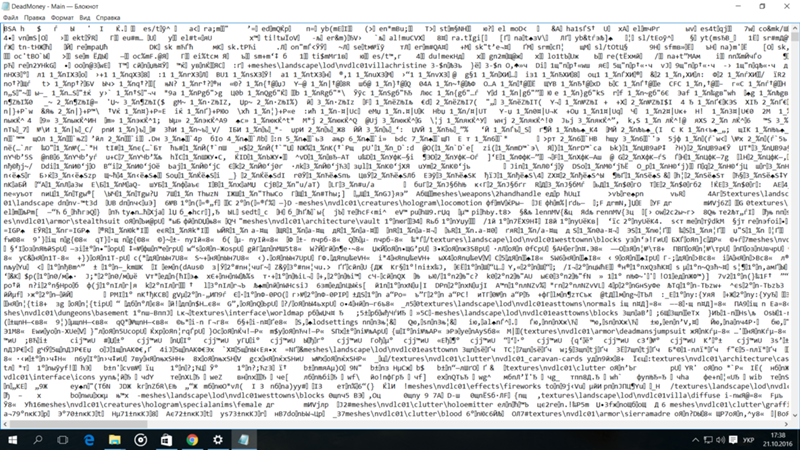
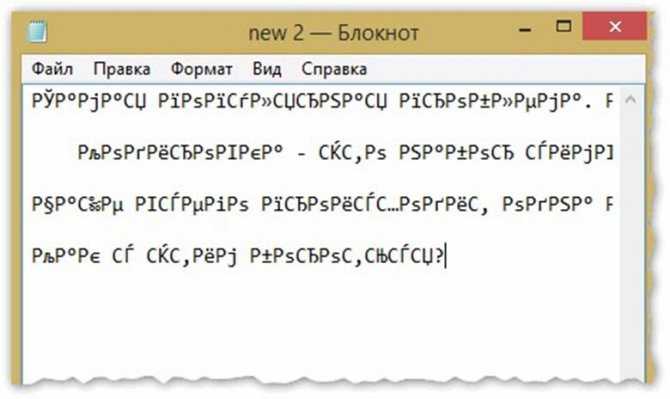
Именно в документах Ворда, Блокнота и т.п. такая кодировка встречается чаще всего. Кодировка – набор знаков, благодаря которым происходит печать текста на определенном алфавите. Теоретически, любой документ сохраняется в различных шифрованиях, но пользователи почти никогда не прибегают к таким действиям. Потому, если Вы видите вместо букв вопросительные знаки и т.п., то маловероятно, что это сделано намеренно. Скорее всего, ввиду системного сбоя у пользователя, создавшего документ, он сохранился не в той кодировки. Кроме того, дело может быть и в сбои на Вашем ПК, в результате чего файл не открывается правильно.
Наиболее часто проблема возникает при использовании Блокнота. Также встречается в файлах php, css, info и подобных текстовых. Гораздо реже в Ворде. Кроме того, путаница с шифрованием встречается в браузере, там Вы также можете увидеть кракозябры вместо русских букв. В последнем случае избавиться от нее особенно трудно.
Notepad +++
Самый простой способ открыть документ Блокнот, где вместо букв квадратики – применить сторонний софт. Популярен Notepad+++. Это тот же Блокнот, но обладающий дополнительными функциями. Имеет следующие преимущества:
- Распространяется бесплатно;
- Как и Ворд, имеет кнопку отмены последнего действия;
- Поддерживает одновременную работу с несколькими файлами;
- Позволяет изменить или выбрать шифрование.
- Автоматически дописывает тексты;
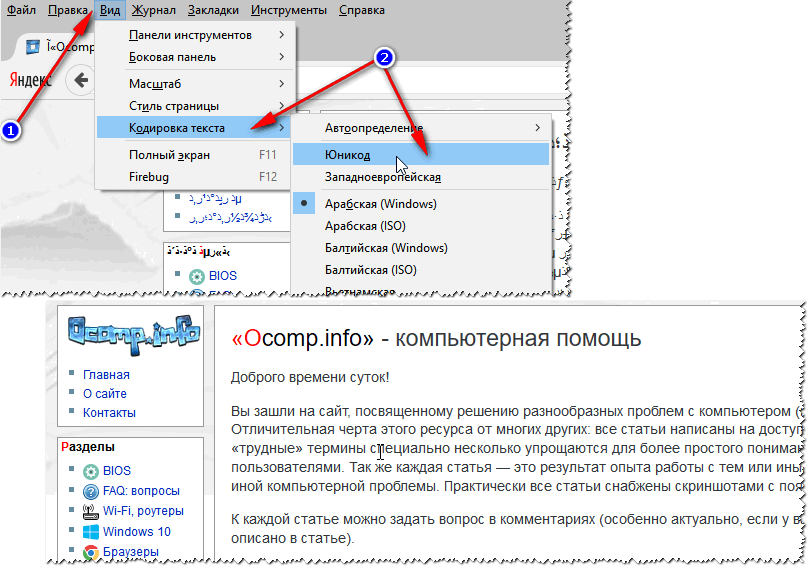
Чтобы иероглифы вместо русских букв преобразовались, откройте документ Блокнота в данной программе. В ленте меню сверху найдите вкладку Кодировки. Нажмите на нее. Откроется меню с перечислением всех их типов. Не всегда очевидно, какой именно тип шифрования применялся, потому, чтобы выбрать правильный для перекодировки, нужно попробовать несколько. Текст пред этим выделите.
По мере применения кодировок, символы в документе могут меняться (по одному нажатию в меню) или оставаться неизменными. В результате, после применения определенной, текст станет читаемым.
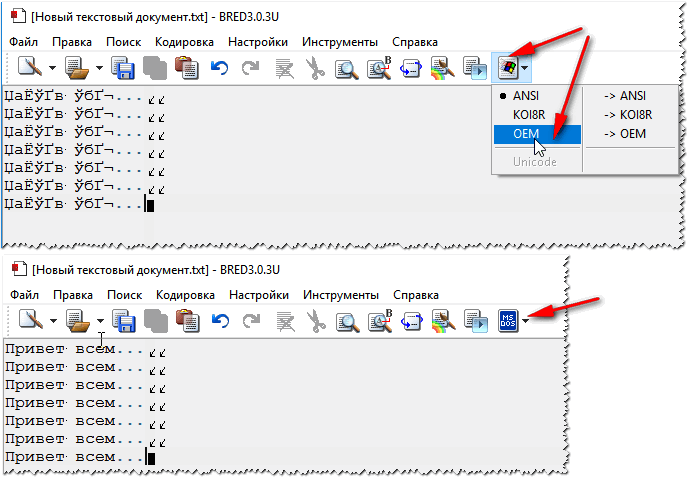
Bred 3
Программа аналогична предыдущей. Представляет собой Блокнот с расширенными возможностями. Успешно применяется вместо стандартного Блокнота Виндовс. Кодировки представлены в отдельной вкладке в верхнем меню. Откройте документ, в котором видны лишь текстовые значки или иероглифы, выделите текст, и пробуйте менять шифрования по очереди. В результате текст станет читаемым.
Поддерживает множество, даже редких, форматов. Работает со старой DOS- кодировкой, которую не открывают современные программы. Работает на Windows 8, 8.1, 10.
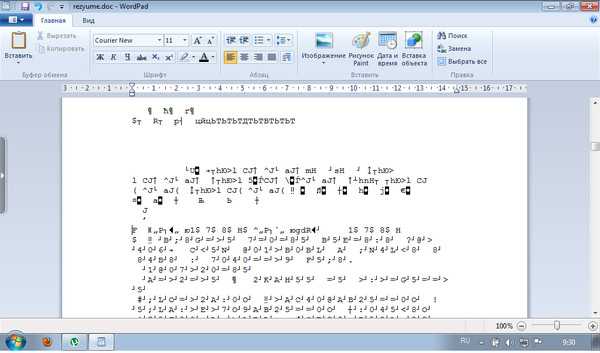
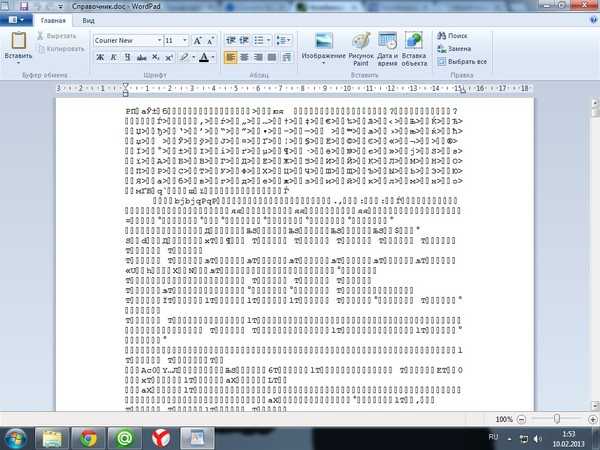

Иногда кодировка появляется и в документах Ворд. Иногда причиной того, что в ворде появились непонятные символы, является то, что у Вас на ПК установлен старый Ворд (до 2007 года), а документ создан в более поздних версиях софта. Чаще всего, такие «новые» файлы просто не открываются в старой версии, но иногда открываются в странной кодировке. Чтобы понять, так ли это, посмотрите в Свойствах файла, какой он имеет формат. «Новые» документы имеют формат docx. Преобразование файла в word до старого формата невозможно. Лучше установить обновление на MS Word. Изменить формат текстового документа на читаемый не сложно.
- Еще до открытия файла, софт «понимает», что в нем проблема. При двойном клике на него Ворд откроет окно, где спросит – в какой кодировке открыть файл. Чтобы изменить кодировку текста в word, выполните алгоритм;
- Попробуйте кодировку, предложенную программой;
- Если не сработало, кликайте по очереди на предлагаемые типы;